Brèves de veille
Zapping Veille du 27/09/24: une banque de données des évidences scientifiques pour les politiques, une nouvelle remise en cause des éditeurs scientifiques, le phénomène des auto-citations


Une banque de données des évidences scientifiques pour les politiques
Des scientifiques veulent créer une banque de données des « évidences » à destination des politiques.
En effet, si le nombre de publications scientifiques ne cesse de croître, elles ne sont, en général, pas destinées à être utiles à la prise de décisions, car ce ne sont pas des synthèses opérationnelles. Deux institutions britanniques, l’ESRC (Economic and social Research Council) et la fondation caritative WELLCOME vont investir respectivement 9,2 et 45 millions de £ sur cinq ans pour produire une banque de données et des outils qui aideront à synthétiser des recherches.
NATURE, 21 septembre 2024
Une attaque contre les grands éditeurs scientifiques
Lucina Uddin, une professeure américaine spécialisée en neuroscience, porte plainte contre six grands éditeurs scientifiques, espérant la transformer en « class action ».
Elle leur reproche de violer les lois antitrust en empêchant un auteur (grâce à une entente, affirme-t-elle) de proposer son article à plusieurs publications en même temps, ce qui ne les incite pas à publier rapidement ces articles. D’autre part, elle considère que la pratique consistant à ne pas payer les évaluations par les pairs (peer reviews) peut s’analyser comme une fixation illégale de prix.
Des auto-citations plus élevées dans 12 pays
Dans un article paru dans PLOS ONE, Alberto BACCINI et Eugenio PETROVICH ont analysé les pourcentages d’auto-citations des auteurs d’articles scientifiques dans 50 pays sur la période 1996-2019.
Si la tendance générale est à la baisse des auto-citations, douze pays font exception : Italie, Colombie, Égypte, Indonésie, Iran, Malaisie, Pakistan, Roumanie, Fédération de Russie ; Arabie Saoudite, Thaïlande et Ukraine.
Ces exceptions semblent être liées, d’après les auteurs, au fait que dans ces pays, le nombre de citations a une influence très directe tant sur la carrière que le salaire des chercheurs.
Zapping Veille du 6/09/24 : Clarivate, Elsevier, et Deloitte innovent avec des solutions IA dans la recherche et l'information numériques

CLARIVATE VEUT RÉVOLUTIONNER LA RECHERCHE AVEC SON ASSISTANT IA POUR WEB OF SCIENCE
Clarivate vient de lancer son assistant de recherche utilisant l’IA générative pour améliorer/optimiser les recherches sur Web of Science Core qui offre 92 millions de références de notices de documents publiés depuis le début du 20° siècle dans tous les domaines de la science avec un accent mis sur les sciences naturelles.
Cette interface a été testée depuis décembre 2023 par plus d’une dizaine de centres de documentation dans le monde utilisateurs de Web of Science.
Nous publierons une « review » détaillée dans le prochain numéro de BASES.
ELSEVIER OUVRE UN CENTRE D'INFORMATION GRATUIT SUR LE MPOX EN RÉPONSE À L'URGENCE SANITAIRE MONDIALE
Elsevier ouvre un accès libre aux éléments cliniques et de recherche concernant le MPOX, la nouvelle maladie potentiellement contagieuse à propose de laquelle l’Organisation mondiale de la santé (OMS) a déclenché une Urgence de santé publique de portée internationale (USPPI) le 14 août 2024.
MOONLIT.AI DE DELOITTE : UNE PLATEFORME IA INNOVANTE POUR LA RECHERCHE JURIDIQUE EUROPÉENNE
Moonlit.ai est un spin-off lancé aux Pays-Bas du cabinet Deloitte, un réseau international de cabinets d’audit.
C’est un outil de recherche et de veille sur les jugements et les décisions juridiques prononcées dans 18 des États membres de la Communauté européenne plus le Royaume-Uni, la Commission Européenne, le Conseil de l’Europe et les Nations Unies. L’utilisation de l’intelligence artificielle permet le multilinguisme, la réalisation de résumé et d’analyses.
Zapping Veille du 30/08/24 : Open access par SPRINGER, référentiels de recherche en France, et intégration d'ARTstor dans JSTOR

L’ÉDITEUR SPRINGER A DÉCLARÉ QUE DÉSORMAIS 44 % DES ARTICLES QU’IL PUBLIE SONT EN OPEN ACCESS
Il présente dans un rapport ses actions en faveur de l’open access déclarant en particulier : « Nous aidons les auteurs de plus de 200 pays à publier en libre accès dans plus de 600 revues entièrement en libre accès et plus de 2 100 revues hybrides, dont Nature Communications, la revue scientifique multidisciplinaire en libre accès la plus citée au monde, et Scientific Reports, la plus grande revue en libre accès au monde (par le nombre d’articles ».
LES RÉFÉRENTIELS DE STRUCTURES DE RECHERCHE EN FRANCE
Le ROR est un référentiel ouvert et mondial des structures de recherche proposant des données sur plus de 110 000 structures. Il a été lancé en 2019 et succède au Global Research Identifier Database. Une curation des données françaises est en train de se mettre en place. Au niveau français, les référentiels des structures sont par exemple :
- le RNSR [Répertoire National des Structures de Recherche géré par le MESR],
- IdRef - [Identifiants et Référentiels pour l’Enseignement Supérieur et la Recherche, géré par l’ABES]
- ou encore AuréHAL [Accès Unifié aux références de HAL – structure gérée par le CCSD].
Sources : LaLIST et Université de Grenoble Alpes
LA PLATEFORME JSTOR INTÈGRE LE CONTENU D’ARTSTOR DIGITAL LIBRARY
JSTOR est une bibliothèque numérique qui donne accès au contenu de milliers de revues académiques. Astor Digital Library est une base de données offrant plus de 2,5 millions d’images destinées à l’éducation et à la recherche dans les domaines de l’art, de l’architecture, des sciences humaines et des sciences sociales.
Zapping Veille du 23/08/24 : une avancée des artistes contre l’IA copieuse, les 7 règles pour des mots de passe sécurisés en 2024, et règlements de censure éditoriale dans 22 pays

LES ARTISTES GAGNENT UNE BATAILLE CONTRE L'IA QUI UTILISE LEURS OEUVRES
D’après le Hollywood Reporter du 13 août 2024, les artistes viennent de remporter une grande victoire dans le litige qui les oppose à la société Stable Diffusion qui propose une IA générative d’images.
Ils lui reprochent d’utiliser leurs créations sans autorisation pour entrainer son moteur d’IA. Un juge américain a considéré leur plainte comme recevable. D’autres sociétés pourraient être inquiétées.
LE CASSE-TETE DES MOTS DE PASSE
CARTOGRAPHIE DES RÈGLEMENTS ET LOIS RÉGISSANT LA CENSURE ÉDITORIALE DANS 22 PAYS
Les motifs de censure des écrits, que ce soit pour la presse ou les livres, sont définis par chaque pays en fonction de ses contextes historique, culturel et philosophique.
Un blog de la Bibliothèque du Congrès des États-Unis présente un rapport sur les lois et régulations en matière de censure dans 22 pays, imposées par les gouvernements pour des raisons de sécurité nationale, de moralité publique, ou de protection des enfants. Ce rapport met en lumière les divers enjeux stratégiques liés à l'accès à l'information dans ces différents contextes nationaux. Le document peut être téléchargé directement.
« Publish or Perish », un jeu de société inspiré de la recherche académique...

« Publish or Perish » est une expression très courante dans les milieux universitaires et de la recherche.
Elle signifie que sans un flux suffisant d’articles publiés dans de « bonnes revues », la carrière d’un chercheur est sérieusement compromise.
Cette préoccupation des chercheurs concernant la publication de leurs articles est une constante dans une carrière et elle est très souvent évoquée, en particulier dans le milieu de la recherche. Elle fait souvent aussi l’objet de polémiques.
L’expression « Publish or Perish » est, en effet, très fréquemment utilisée, et ce, depuis longtemps, si l’on en juge par le nombre de réponses affichées par Google, à savoir 964 000, même si l’on sait que l’on ne pourra pas toutes les visualiser. Le serveur Dialog quant à lui annonce que 19 400 documents contiennent l’expression, documents que l’on peut, en théorie, effectivement visualiser.
Peu d’expressions couramment employées, surtout dans le milieu professionnel, en particulier si elles sont quelque peu polémiques, deviennent le prétexte d’un jeu de société. C’est pourtant ce qui est en train d’arriver avec cette expression. En effet, d’après la publication bien connue NATURE, un psychosociologue américain du nom de Max BAI a lancé en bêta un jeu s’appelant « The Publish or Perish game ».
Ce jeu de société centré sur la publication académique — ce qui est très original — ressemble au bien connu et historique Monopoly, à ceci près que le vainqueur est celui qui a obtenu le plus grand nombre de citations d’articles qu’il a publiés. Mais tout cela se passe de façon caricaturale, le plagiat étant possible, voire encouragé, de même que le sabotage des actions des chercheurs concurrents au moyen de dénigrement ou en leur faisant subir des restrictions budgétaires.
Nous ne résistons pas au plaisir de citer les titres de certains de ces articles improbables :
« Unpacking the Aerodynamics of Flying Pigs », « Why Dogs Follow You Into the Bathroom: Insights into Canine Codependency » ou encore « The economics of Santa Claus: an analysis of infinite resource management ».
Ce jeu peut tout à fait séduire le grand public, mais les éléments satiriques auront une résonance particulière pour ceux qui auront passé suffisamment de temps dans le milieu universitaire.
D’après l’article de Nature dans lequel nous avons trouvé cette information, le jeu sera en vente dans quelques mois sur la plateforme Kickstarter. Pour être informé du lancement effectif du jeu, vous pouvez vous inscrire ici.
Un recensement mondial des publications disponibles en ligne
Fulltext Sources Online recense depuis de très nombreuses années les publications du monde entier disponibles en texte intégral sur au moins un agrégateur, parmi les 17 qu’il prend en compte.
Il n’y a plus qu’une édition annuelle au lieu de deux précédemment, mais il y a une version en ligne librement recherchable, les détails des publications étant réservées aux abonnés.
Quelques chiffres
Un total de 64 636 publications sont recensées dont 467 françaises (BASES et NETSOURCES en font partie), mais 1 928 en français, tandis qu’il y a une publication en occitan et trois en islandais.
Sans surprise, pour les titres en français, plus de 80 commencent par Journal, plus de 70 par Revue, 28 par ECHO ou L’Echo, 17 par La Lettre, etc.
On notera l’absence d’agrégateurs de presse européens tels que ADAY pour la France, GBI Genios pour l’Allemagne, Swissdox pour la Suisse et Belga pour la Belgique.
Leur prise en compte aurait conduit à largement dépasser le nombre actuel de publications recensée.
DeepL annonce surpasser ses concurrents

La société allemande DEEPL, un des acteurs majeurs de la traduction automatique, annonce qu’il va surpasser ses concurrents que sont Google Translate et ChatGPT.
Cela devrait se faire grâce à son dernier modèle de langage LLM.
En effet, ce nouvel LLM ne s’appuie pas, pour s’entrainer, sur des données d’Internet en général, mais sur son propre jeu de données propriétaires sélectionnées et adaptées à la création de contenu et à la traduction linguistique.
Il prétend donc qu’il sera meilleur que Google Translate qui rencontre des problèmes de traduction littérale ou incorrecte.
Quant à ChatGPT, son offre de traduction automatique serait secondaire par rapport à l’ensemble de son offre alors que "DeepL est très spécialisé, ce qui est particulièrement utile dans des domaines exigeant une haute précision ». Bref, il sera meilleur là aussi.
Ces améliorations devraient faire gagner en temps et en efficacité, car il y aura moins de temps consacré à la vérification et à la correction.
Loin de vouloir concurrencer les traducteurs professionnels il se positionne comme leur « allié indispensable », une affirmation qui peut laisser songeur...
Google accélère fortement sur les langues

Google intensifie sa politique de diversité linguistique en annonçant l'ajout de huit nouvelles langues aux options de traduction de ses résultats de recherche, portant le total à 21. Parmi les langues ajoutées figurent l'arabe, le gujarati (une langue indienne), le coréen, le persan, le thaï, l'ourdou (parlé en Inde et au Pakistan), et le vietnamien.
Par ailleurs, Google Translate s'enrichit considérablement avec l'introduction de 110 nouvelles langues, y compris des langues régionales de France telles que le breton et l'occitan.
Les langues africaines sont également mises à l'honneur, un quart des nouvelles langues étant parlées sur le continent africain, comme le wolof, le fon, le kikongo.
Par ailleurs, on notera le tibétain et le cantonais, principal dialecte chinois depuis longtemps réclamé. Ces ajouts permettent à Google Translate de toucher plus de 614 millions de personnes supplémentaires.
Cette initiative s'inscrit dans le cadre du projet ambitieux lancé en 2022 visant à traduire les 1 000 langues les plus parlées à travers le monde.
En outre, Google améliore la reconnaissance vocale en apprenant à comprendre une multitude d'accents issus de diverses langues, renforçant ainsi son accessibilité et sa pertinence à l'échelle mondiale.
Zapping Veille du 12/07/2024 : Clarivate réévalue l'impact des citations, l'OCDE ouvre ses données, les recherches scientifiques anciennes peuvent toujours être pertinentes

Quand les informations scientifiques anciennes sont toujours d’actualité
Nous signalons ici un post très intéressant sur le site de CLARIVATE : “'Sleeping beauties’: Yesterday’s findings fuel today’s research breakthroughs”
Valentin Bogorov, l’auteur, explique en se basant sur de nombreux exemples que l’art antérieur récent ou les connaissances les plus récentes ne sont pas nécessairement les plus intéressantes à prendre en compte dans la recherche.
Les exemples qu’il cite proviennent de domaines très différents. Il illustre son propos avec l’évolution des citations d’un article publié en 1948 intitulé “An Approach Toward a Rational Classification of Climate” écrit par Charles W. Thornthwaite, un éminent géographe et climatologue américain qui a peu retenu l’attention jusqu’à l’année 2 000. À aujourd’hui, il a été cité plus de 5 900 fois par des chercheurs de 143 pays, sachant que plus de 90 % des citations sont postérieures à l’an 2000.
Suspension du facteur d’impact pour 17 publications : Clarivate sanctionne les autocitations
CLARIVATE est l’éditeur du Journal Citation Reports. Il produit le facteur d’impact (Impact Factor) qui est calculé par une formule qui prend en compte le nombre de citations des articles d’une publication.
Bien qu’il soit controversé, le facteur d’impact est l’indicateur de la notoriété d’une publication le plus utilisé actuellement. Il contribue, en particulier, à évaluer la qualité du travail des chercheurs.
Pour l’édition 2024, 17 publications ont perdu leur facteur d’impact à cause d’une suspicion de manipulation des citations. Il leur est reproché, en particulier, d’avoir abusé des autocitations.
Toutes les données, publications et analyses de l’OCDE sont désormais accessibles gratuitement
Grâce à La licence Creative Commons CCBY 4.0, l’OCDE adopte un modèle libre d’accès. Le site offre un catalogue de près de 30 000 éléments consultables, téléchargeables et partageables.
Zapping Veille du 5/7/24 : Les dernières innovations en IA avec SCOPUS AI d’Infotoday, la plateforme Lexis+AI, les illustrations en réalité augmentée de Karger et 37% des recherches Google sans clic!

Notre article sur SCOPUS AI publié par l’éditeur américain Infotoday
Notre article sur SCOPUS AI paru dans le numéro 425 (Mai 2024) de BASES a été publié en anglais parmi les « featured articles » sur la plateforme de l’éditeur américain Information TODAY.
LexisNexis a lancé en France ce 1° juillet Lexis+AI, une plateforme de recherche et d’analyse juridique
Cette solution d’IA générative permet d’interagir avec la base de données juridique de LexisNexis et ses contenus exclusifs. Elle fournit des liens directs vers les sources citées dans les réponses, permettant ainsi de réduire le risque de sources inventées.
Les illustrations d’articles scientifiques de Karger en réalité augmentée en 3D
Cela ne concerne cependant pas tous les articles, sans que l’on sache quel est le critère.
Un gros tiers de recherches sur Google n’aboutissent à aucun clic
Rand Fishkin est cofondateur et CEO de SparkTORO qui propose des logiciels dans le domaine de l’analyse des audiences.
Il vient de publier un article faisant apparaître qu’environ 37% des recherches menées sur Google ne sont suivies d’aucun clic, ce résultat étant valable aussi bien aux Etats-Unis qu'en Europe.
Zapping Veille du 28/6/24 : Businesscoot utilise l'IA pour les recherches sectorielles avec Indexpresse - l'IA générative bouleverse les médias et le droit d'auteur - ResearchGate élargit son offre op ...

BUSINESSCOOT, spécialiste français des études sectorielles, rachète INDEXPRESSE
Nouvelle étape pour la longue vie de la banque de données Delphes qui était commercialisée ces dernières années par IndexPresse.
Businesscoot, spécialiste français des études sectorielles rachète Indexpresse. Cela conduira à l’offre SectorGPT qui grâce aux informations des études ajoutées à celles de la banque de données Delphes proposera des recherches sectorielles en utilisant l’IA.
Les réponses sont annoncées comme fiables et traçables.
Le "nouvel IndexPresse" étant commercialisé prochainement, nous le testerons de façon complète dans le BASES de septembre 2024.
"Journalisme de confiance à l’ère de l’IA générative" : la question du droit d'auteur vue par L’EBU News Report
L'IA générative est un facteur potentiel de redéfinition du paysage médiatique, transformant en profondeur la manière dont les contenus sont créés et distribués. Elle menace ainsi les modèles économiques traditionnels qui reposent fortement sur les droits d'auteur pour générer des revenus.
- Protection du copyright et transparence : les systèmes d'IA doivent créditer correctement les sources et assurer une rémunération équitable aux titulaires de droits. Les propriétaires des systèmes d'IA sont appelés à maintenir un registre transparent du contenu journalistique utilisé.
- Utilisation des données : comment les médias et journalistes doivent-ils naviguer dans un paysage dans lequel les modèles de langue peuvent utiliser leur contenu sans permission explicite?
- Des modèles de gouvernance : les médias et ingénieurs de l’IA doivent collaborer pour créer des modèles de gouvernance respectant les droits d'auteur tout en soutenant l'innovation.
Lire aussi : Le droit d’auteur face à l’IA générative : Interview de Philippe Masseron (gf2i) sur les enjeux juridiques et économiques des métiers de l’information et de la donnée.
ResearchGate continue à charger des publications en open access
Comme nous l’avons décrit dans notre récent article de BASES : « ResearchGate développe ses liens avec les éditeurs », ce réseau social continue à développer son activité d’agrégateur.
Il a ainsi chargé récemment :
Auto-News – un agrégateur de news intelligent à base d'IA

20 juin 2024 - Résumé généré par IA à partir de l'article original de Korben (Auto-News – L’agrégateur de news qui vous permet d’éviter le « bruit »)
- 🚀 Agrégateur automatisé : Auto-News rassemble vos sources favorites (tweets, RSS, YouTube, articles web, Reddit, notes perso).
- 🤖 Analyse IA : L’IA analyse, résume et trie le contenu rapidement, ne gardant que l’essentiel selon vos intérêts.
- 🗂️ Organisation : Créez une page Notion, ajoutez vos tokens, et Auto-News organise vos contenus en dossiers et bases de données.
- 📱 Sources personnalisées : Indiquez vos flux RSS, comptes Twitter et Reddit favoris pour personnaliser les contenus.
- 🎥 Transcriptions vidéo : Générez des transcriptions pour vidéos YouTube et articles web pour une lecture rapide.
- 📝 Listes de tâches : L’IA crée des listes de tâches à partir de vos notes et réflexions.
- 💻 Compatibilité : Fonctionne sous Linux ou MacOS, avec Docker pour le déploiement, et une interface Notion accessible sur iPhone, Android ou navigateur.
Rechercher des articles de presse : les Netflix de l’info vont-ils faire flop ?

Il y a quelques années, les kiosques numériques comme Cafeyn, E-presse ou encore Pressmium s’annonçaient comme l’avenir de la presse française et se voyaient déjà comme les Netflix ou Spotify de l’information.
Avec un tarif très abordable et la possibilité d’accéder en un seul et même endroit à de très nombreux titres de presse française et internationale, ils avaient, sur le papier, tout pour séduire les personnes à la recherche d’articles de presse ou souhaitant mettre en place une veille d’actualités. Sur le papier seulement…
Aujourd’hui, force est de constater qu’on est très loin du compte et que le soufflé semble retomber. Les kiosques numériques sont-ils en perte de vitesse ? Quelles solutions existe-t-il aujourd’hui pour rechercher des articles de presse et mettre en place une veille « médias » ?
Zapping Veille du 21/6/24 : Dimensions ajoute des références africaines, le gf2i élit un nouveau bureau, Tagaday migre vers une nouvelle plateforme, Digimind intègre l'IA dans AI Sentinel

Des références à de la littérature scientifique africaine vont être ajoutés dans le site de Dimensions.
Nous en parlerons plus en détail dans notre prochain numéro de BASES de juillet août 2024.
Le gf2i élit un nouveau Président et bureau pour relever les défis de l'accélération technologique
Le gf2i a élu un nouveau bureau dirigé par Thomas Parisot, avec un conseil d'administration élargi, afin de relever les défis liés à l'accélération technologique et faire de la transition numérique un levier de valeur pour l'économie et la société.
Tagaday annonce l'arrêt de son ancienne plateforme le 30 juin 2024
À partir du 30 juin 2024, l'ancienne version de la plateforme Tagaday ne sera plus accessible. L'ensemble des comptes sera opérationnel sur la nouvelle plateforme, plus moderne et intuitive, offrant des fonctionnalités innovantes pour faciliter le suivi des retombées médias.
Digimind intègre l'IA dans son outil de social listening AI Sentinel
L'OMPI annonce les 25 finalistes des Prix mondiaux 2024
Et si demain ChatGPT et autres IA génératives disparaissaient ? Nous avons demandé à ChatGPT et à Claude de nous dire ce qui se passerait...

Il aura finalement fallu très peu de temps pour que nous nous sentions maintenant dépendants des IA génératives telles que ChatGPT, Claude, Gemini, Mistral et bien d'autres dans notre organisation et processus d’entreprise.
S'y ajoutent tous les outils, plugins et applications que nous testons et intégrons progressivement dans nos activités professionnelles. Peu importe que la pérennité de ces applications soit souvent incertaine, nous en changeons avec la même facilité que nous les avons adoptées.
Car c'est là la "magie" de l'IA : la transformation d'une tâche, d'un processus ou d'un livrable ne tolère pas de retour en arrière.
Pourtant, la menace existe, qui se réactive dans nos esprits au moindre incident de ChatGPT (ils sont nombreux). On a pu encore en faire l’expérience lors de très récente panne de plus d’une journée de Copilot (ex BingChat).
Que se passerait-il si l'IA générative ne nous était plus accessible ? et quel en serait l’impact sur notre organisation de travail déjà modifiée par les apports successifs des différentes SIAG (systèmes d’intelligence artificielle générative) ?
Retrouvez-nous à Documation 2024
Ne manquez pas cette opportunité unique d'enrichir vos connaissances et d'échanger avec des spécialistes du domaine. Réservez dès maintenant votre place et venez découvrir comment la veille externalisée peut propulser votre entreprise vers le succès !
Nous avons hâte de vous retrouver à cet événement incontournable de l'industrie de la gestion de l'information et de la veille stratégique !
Aidez-nous à façonner les Bases & Netsources de demain : participez à ce sondage.

Chères lectrices, chers lecteurs,
Nous lançons ce grand sondage destiné à tous nos abonnés et lecteurs réguliers ou irréguliers, afin de recueillir des informations précieuses sur vos besoins, vos préférences et attentes. Cela nous permettra de réévaluer notre ligne éditoriale et de créer des contenus qui répondent à vos besoins spécifiques.
Merci de votre participation !
L’actualité sous l’angle de la veille et de la recherche d’info - Brèves de veille de février

Au sommaire de ce numéro, 3 actualités soigneusement sélectionnées qui pourront avoir un impact sur les professionnels de l’info, veilleurs et analystes à court ou moyen terme.
Google SGE met en avant des pages habituellement absentes de la première page
IST et IA – Le passage à l’indexation automatique dans Medline et Pubmed : 47% des articles contiennent désormais des erreurs
L’essor des newsletters locales
SEARCH - Google SGE met en avant des pages habituellement absentes de la première page
Une récente analyse d'Authoritas sur Google SGE (la fonctionnalité d’IA de génération de réponses directement intégrée en haut des résultats de Google mais qui n’est pas encore disponible en Europe) a révélé que les réponses générées par SGE ne correspondent presque jamais (dans 93.8% des cas) aux liens des 10 premiers résultats de recherche organique.
Pourquoi c’est intéressant :
Cela pourrait donc permettre à des sites habituellement mal référencés ou en tout cas absents du top 10 d’être plus visibles. Et par extension, pour le professionnel de l’information de voir des pages et sites pertinents qu’il n’avait pas nécessairement l’habitude de voir apparaître. Mais attention à ne pas se réjouir trop vite : SGE vient tout juste d’arriver et personne ne sait encore quelles sont les techniques et méthodes pour réussir à bien s’y positionner. Quand ce sera le cas, il est possible que les sites habituellement bien référencés reprennent tout simplement leur position de leaders…
Toujours est-il qu’il y a quand même une tendance générale à vouloir mieux faire émerger des contenus de qualité, mais peu visibles :
- Cela rappelle ce que nous évoquions dans la précédente newsletter avec l’actualité « Google et X (Twitter) veulent mieux mettre en valeur les trésors du Web » ;
- Et toujours dans cette même veine, au mois de décembre dernier, Google avait annoncé qu’il allait mettre plus souvent dans les premiers résultats les sites que l’on visite souvent, sites qui sont donc pertinents pour nous, mais pas obligatoirement champions du référencement.
Et sinon, on peut continuer à utiliser les méthodes des professionnels des informations pour aller dénicher des pépites et trésors sur le Web :
- Sourcing, de la théorie à l’épreuve de la pratique
- Comment enrichir son sourcing grâce à Google Sheets, Airtable & les autres ?
- Identifier des podcasts pour sa veille
- Sourcing : comment détecter des médias réellement nouveaux ?
- Veille internationale : comment trouver des sources en langue étrangère ?
IST et IA – Le passage à l’indexation automatique dans Medline et Pubmed : 47% des articles contiennent désormais des erreurs
On s’intéressera maintenant à une présentation qui a été faite lors de la conférence annuelle 2023 de l’association des bibliothèques de la santé du Canada et dont le support vient d’être récemment mis en ligne à propos de l’usage de l’indexation (MeSH) par IA dans Medline.
On rappellera que dans Medline et PubMed, les articles sont indexés avec un système de mots-clés hiérarchisés appelé MeSH (Medical Subject Headings). Et cela s’avère très utile pour la recherche d’information.
Depuis avril 2022, tous les articles se voient attribués leur MeSH via l'indexation automatisée (IA). La présentation examine la capacité de l'IA à identifier et représenter correctement les concepts clés d'un article. Les résultats montrent que 47 % des articles examinés présentaient des problèmes au niveau des MeSH, affectant ainsi leur récupération potentielle lors de recherches.
Pourquoi c’est intéressant :
Le basculement à un système d’indexation 100% IA montre à ce stade une dégradation de la qualité de l’indexation et par extension de la recherche. Car on aura dans les résultats à la fois plus de bruit avec des articles non pertinents qui ont reçu des MeSH qui ne les concernent pas et à la fois un risque accru de passer à côté d’articles pertinents qui, eux, n’ont pas reçu le(s) MeSH qu’ils devraient avoir.
La recherche via l’indexation MeSH ne peut ainsi plus, à ce stade, être considérée comme aussi fiable que le passé et nécessite une attention accrue.
Il est donc nécessaire de ne pas se reposer uniquement sur l’indexation pour effectuer ses recherches mais aussi de réaliser des recherches par mot-clés classiques sur le titre, abstract, etc.
On comprend en lisant la présentation que la vérification par un humain de l’indexation automatisée n’a ici rien de systématique : « Selon la NLM (National Library of Medicine), les MeSH attribués par l'IA sont déterminés sur la base des termes du titre, du résumé et des termes et de l'indexation des enregistrements "voisins et connexes", avec un examen humain et une curation des résultats "le cas échéant". »
Et cela n’augure rien de bon pour l’avenir de Medline et Pubmed en termes de qualité d’indexation. L’IA peut indéniablement avoir un rôle à jouer pour l’indexation en faisant gagner du temps et en ingérant de très gros volume de données mais l’IA fait aussi beaucoup d’erreurs et a besoin d’être améliorée, corrigée et entraînée en permanence. Il y a donc besoin d’une couche de vérification humaine pour corriger les erreurs mais aussi améliorer l’algorithme.
Sur ce thème, on conseillera un récent épisode du podcast « Le code a changé » de France Inter intitulé « Les dames de l’algorithmes » qui nous parle d'un groupe d'annotatrices travaillant pour le Palais de Justice et qui entraînent un programme d'IA sur un programme d'anonymisation automatique des décisions de justice. Et qui nous rappelle par la même occasion que l’IA n’a rien de magique et que derrière, il y a souvent beaucoup d’humain !
Pour aller plus loin sur la question de l’intégration de l’IA dans les métiers de l’information :
TENDANCES – L’essor des newsletters locales
Faire de la veille, c’est d’abord réussir à identifier les meilleures sources d’information sur les sujets qui nous intéresse. Et ces sources peuvent se présenter sous de multiples formats : sites Web, blogs, comptes sur les réseaux sociaux, mais aussi de plus en plus newsletters.
Et l’une des tendances que l’on peut observer du côté des newsletters, c’est la multiplication de newsletters locales ou hyperlocales développées par des médias et journalistes à travers le monde.
Le magazine britannique The Lead a par exemple annoncé le lancement de 10 newsletters locales, chacune dédiée à une ville du nord de l’Angleterre. Toujours en Angleterre, on retrouve ce modèle de newsletter locale comme avec The Mill, une newsletter d’actualités dédiée à la ville de Manchester ou The Sheffield Tribune pour la ville de Sheffield. Et en France, Nice Matin ne cesse de développer son offre de newsletters locales. Derniers ajouts en date : FicaNice pour Nice et De la Rade au Faron pour Toulon.
Pourquoi c’est intéressant :
Quand on a une dimension locale à inclure à sa veille en France ou à l’international, on ne pense pas nécessairement aux newsletters locales, d’autant que les newsletters ont eu un gros passage à vide pendant des années avant de revenir en force depuis quelques années (voir notre article de 2021 « Substack ou le symbole du retour en force des newsletters pour la veille »).
On a donc grandement intérêt à aller investiguer dans la direction de newsletters locales même si elles ne sont pas toujours faciles à identifier.
Dans notre récent article « Sourcing : l'info locale se renouvelle », on décrypte pour vous cette tendance des newsletters locales mais aussi les nouvelles formes que peut prendre l’information locale bien loin du schéma traditionnel du titre de presse classique et on vous explique comment réussir à les identifier.
Choisir son corpus avec Perplexity, moteur de recherche dopé à l’IA
Perplexity est le seul outil IA positionné comme un moteur de recherche. Il fonctionne avec GPT et son modèle propriétaire (Pplx). Il vient de s’améliorer en permettant de sélectionner son corpus. Cette fonctionnalité, discrète, se cache derrière le bouton « Focus ».
Il propose de filtrer ses recherches par corpus : Academic (en provenance de Semantic Scholar), Wolfram/Alpha (pour l’informatique), YouTube et Reddit, mais aussi par format (image ou vidéo).
C’est un bon moyen pour réduire la marge d’erreur (et donc le niveau d’hallucination) de l’outil et d’améliorer la précision des résultats. Last but not least, cela permet aussi de savoir d’où viennent les sources.
Par exemple, si l’on cherche Hemingway, puis que l’on choisit « Youtube », six vidéos sont proposées, suivies par une courte biographie (générée) et de trois questions suggérées. À droite, trois autres vidéos sont proposées, ainsi qu’une « Recherche Image » et une « Génération d’image » (accès payant). Pour une recherche filtrée avec des résultats en provenance du forum « Reddit », il nous est aussi proposé une « recherche video ».
L’actualité sous l’angle de la veille et de la recherche d’info - Brèves de veille de janvier

|
|---|
|
|---|
Masterclass Veille & Search 2024 - Ouverture billetterie
Cher(e)s ancien(ne)s et potentiel(le)s futur(e)s participant(e)s,
Nous espérons que ce message vous trouve en pleine forme. Nous sommes ravis de vous annoncer que la billetterie en ligne pour nos sessions de formation MasterClass Veille & Search 2024 est désormais ouverte !
Cette année, nous vous proposons deux sessions thématiques :
- Le 25 mars 2024 découvrez l’IA avec la Masterclass : Dompter la puissance de l’IA pour sa veille.
- Le 26 mars 2024, maîtrisez le RSS avec la Masterclass : VEILLE RSS : La solution professionnelle sans plateforme.

Ces MasterClass promettent d'être une expérience incontournable pour les professionnels de l’information que vous êtes. Nous avons rassemblé nos experts FLA Consultants et Bases publications pour vous offrir des sessions enrichissantes, interactives et axées sur la pratique.
Pour vous inscrire et obtenir plus d'informations sur les tarifs, les dates et le programme complet des MasterClass Veille & Search 2024, veuillez cliquer sur le lien ci-dessous :
Si vous avez des questions, si vous avez besoin d’un devis personnalisé, si vous souhaitez vous inscrire en direct et ne pas passer par la billetterie ou avez besoin d'assistance pour votre inscription, notre équipe est là pour vous aider. Contactez-nous à
L’actualité sous l’angle de la veille et de la recherche d’info - Brèves de veille de décembre

L’actualité sous l’angle de la veille et de la recherche d’info.
Au sommaire de ce numéro, 3 actualités très récentes soigneusement sélectionnées qui pourront avoir un impact sur le pro de l’info à court ou moyen terme.
- VEILLE - LinkedIn s’ouvre à la veille
- SEARCH - Google teste l’ajout de notes humaines dans ses résultats de recherche
- IST – Lancement officiel de GETFR, un nouveau plugin d’accès aux articles académiques
VEILLE – LinkedIn va s’ouvrir à la veille
En bref :
LinkedIn a longtemps été le réseau social le plus fermé à la veille et aux outils de veille. Mais cela est en train de changer d’après Antoine Khaitrine (Licter).
Dans un post LinkedIn, il annonce que :
- Les gros acteurs du social media monitoring notamment américains vont très prochainement avoir accès à une API et vont ainsi pouvoir intégrer la surveillance de LinkedIn à leur corpus ;
- Du côté français, Digimind proposait depuis un moment déjà une surveillance de LinkedIn et que Visibrain serait sur le point de faire de même.
Pour en savoir plus : https://www.linkedin.com/posts/antoine-khaitrine_linkedin-souvre-au-social-listening-activity-7133505793143771136-KfVo?utm_source=share&utm_medium=member_desktop
Pourquoi c’est intéressant pour le pro de l’info
LinkedIn est un réseau social très bien positionné pour répondre aux besoins informationnels des veilleurs et documentalistes. Mais la recherche comme la veille n’y a jamais été satisfaisante. Cette annonce d’ouverture est une bonne nouvelle certes, mais en demi-teinte.
Pour le moment, l’ouverture des données semble surtout s’adresser aux gros acteurs du social media monitoring, ceux qui ont les moyens de payer. Ce sont les mêmes que ceux qui n’ont pas été impactés par la fin de l’API gratuite de Twitter car ils payaient déjà pour l’API payante depuis des années. Les pro de l’info, clients de ces acteurs vont donc être indéniablement gagnants.
Pour les clients des autres plateformes de veille plus traditionnelles ou mêmes des lecteurs RSS type Inoreader ou Feedly, rien ne garantit que la surveillance de LinkedIn soit une de leur priorité. On a pu le voir avec Twitter (désormais X), la fin de l’API gratuite a tout simplement été la fin de la fonctionnalité de surveillance de Twitter dans ces plateformes. L’intégration de LinkedIn ne sera probablement envisagée que si le coût de l’API est abordable et/ou la demande des clients massive. Il va donc falloir, pour le moment, continuer à surveiller LinkedIn avec les « moyens du bord » comme on l’a toujours fait : voir notre article Réussir à utiliser LinkedIn pour la veille et la recherche d’information.
On suivra avec attention les annonces de LinkedIn dans les prochains mois pour voir si, en parallèle d’une API Entreprise onéreuse, LinkedIn envisage de déployer une API moins perfectionnée mais satisfaisante et surtout gratuite ou abordable. C’est seulement dans ce cas de figure que pourront se développer des fonctionnalités de surveillance au sein des outils de veille existants ou tout un écosystème de nouveaux outils de surveillance et d’analyse comme cela était le cas sur Twitter avant la fin de l’API gratuite.
Pour aller plus loin :
Conseil veille pour réaliser une veille sur les pages Entreprises sur LinkedIn
La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée
LinkedIn, une alternative crédible à Twitter pour la veille ?
Veille commerciale sur LinkedIn, tirer parti des filtres pour trouver des prospects
Stynch, un outil d’analyse de profils LinkedIn façon dataviz
SEARCH - Google teste l’ajout de notes humaines dans ses résultats de recherche
Comment trouver des podcasts sans Google : pensez à Kagi Search
Google Podcasts va prochainement disparaître pour être intégré dans YouTube Music. Aussi, sur le moteur Web de Google, l'apparition du filtre "podcast" est complètement aléatoire, ce qui complique la recherche méthodique et rigoureuse de ce précieux support d'informations.
Nous vous conseillons donc de parcourir Kagi Search, qui a consacré un onglet spécial pour les podcasts ! Le crawler va rechercher le mot-clé dans le titre du Podcast, le titre d’un épisode et dans le descriptif de ces derniers.
Pour cela, il suffit de taper son mot-clé dans la barre de recherche, puis de cliquer sur l’onglet « Podcast » sous la barre de recherche. Les résultats s’affichent tout d’abord sous forme d’une galerie avec visuels des Podcasts, puis une série de podcasts sur le sujet donné.
Résultat : cette recherche permet de belles découvertes, y compris d’épisodes récents (moins de 48 heures), mais elle n’est pas exempte de bugs : des résultats de la galerie renvoient vers des erreurs 404, d’autres manquent de pertinence et peuvent même constituer une perte de temps : une recherche « Macron » renvoie sur quelques chroniques politiques, mais alors que le résultat fait apparaître le titre d’un épisode, le lien nous envoie sur une longue liste d’épisodes… dans laquelle ne figure même pas le titre de l’épisode sur lequel on a cliqué.
Conclusion : une initiative qui vaut le détour, mais qui demande à être encore améliorée. Et pour aller plus loin ne ratez pas notre article complémentaire : Identifier des podcasts pour sa veille
Les APIs : une nouvelle piste pour la veille ?

Dans le secteur de l’information, il est un acronyme qui revient régulièrement : l’API. On comprend bien qu’il s’agit d’une porte d’accès à des données et à des services, donc des informations, mais sont-elles exploitables pour le veilleur ? Voici le premier de deux billets pour répondre à cette question.
Décryptage, ce qu’est une API
API est l’acronyme de Application Programming Interface, ou Interface de programmation d’application en français. Il s’agit donc d’un moyen de connexion entre différentes applications (ou composants d’applications), grâce à une interface.
Au départ, l’exploitation des APIs était réservée aux développeurs. Mais cela est en train de changer avec l’utilisation des outils no code. Les outils d’automatisation fonctionnent avec les APIs des outils. Ce sont elles qui garantissent l’accès, la synchronisation et ce qu’il est possible de « tirer » d’un outil. Le professionnel de la veille en manipule donc déjà sans le savoir. Zapier, Make ou IFTTT les utilisent déjà de façon quasi invisible car ils se connectent à des APIs et permettent aussi à des outils de s’y connecter. On peut ainsi non seulement accéder à des APIs mais aussi ouvrir son accès à une API pour partager des informations dont on reste maître.
Les APIs concurrencent-elles les flux RSS et constituent-elles un trésor encore sous-estimé ?
Les API et les flux RSS/JSON sont donc tous deux des moyens de récupérer et/ou de fournir des données à des applications. Ils présentent certains points communs, mais aussi des différences importantes.
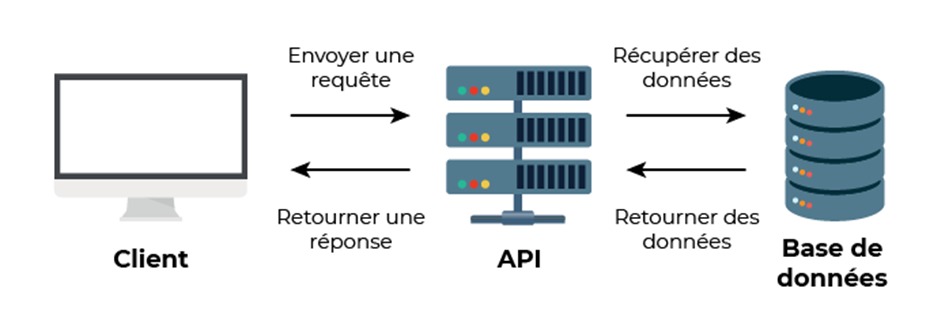
Figure 1 : Copyright - DR
Points communs
- Ils permettent d'accéder à des données provenant d'autres sources.
- Ils peuvent être utilisés pour fournir une variété d’informations : sur les produits, les services, les événements, les actualités, etc.
- Ils peuvent servir à automatiser des tâches.
- Ils peuvent avoir un format commun : le JSON (rappelons au passage que le JSON n’est pas du code car il n’y a pas de « logique », mais qu’il s’agit simplement d’une manière de présenter les données).
Les veilleurs face au déclin de X (Twitter) - Brève de veille de novembre
Les veilleurs face au déclin de X (Twitter)
Avec l’inexorable déclin de X (Ex-Twitter), il est temps pour les veilleurs et documentalistes de réfléchir sans trop tarder à un (ou plusieurs) plan B si ce n’est pas déjà fait et réduire son exposition à X au cas où il ne serait même plus accessible.
On commencera par rappeler que, dans nos métiers, les réseaux sociaux ont un double usage :
- En premier lieu pour faire sa veille métier et retrouver la communauté des veilleurs et documentalistes pour échanger et partager sur ses pratiques ;
- En second comme une source parmi d’autres pour les veilles qu’on réalise pour ses clients, usagers qu’ils soient internes ou externes à son organisation.
Et si Twitter a longtemps été en mesure de répondre à ses deux besoins, force est de constater qu’aucun réseau social n’est aujourd’hui capable d’englober ces deux dimensions. C’est d’ailleurs pour cela que la veille sur les réseaux sociaux aujourd’hui ne peut être que multiple. Ou alors, plus radical, il faut faire le choix de totalement s’affranchir des réseaux sociaux au profit d’autres types de sources.
Lire aussi :
La veille métier, une veille pas comme les autres
Pour ne rien rater, pensez à vous abonner à notre newsletters augmentées !
La commande filetype:CSV enfin possible sur Google !
Dans la famille des file-types indexés par Google, il y avait un grand absent qui pouvait être regretté par les professionnels du Search et de l’analyse des données : le format de tableau de données .CSV
Depuis quelques semaines, les fichiers et tableurs Excel (Microsoft), Numbers (Apple) ou les autres logiciels qui produisent du .CSV peuvent donc être retrouvés (sans avoir à faire d’export, par exemple). Ils rejoignent les fichiers texte, image ou vidéo, mais aussi les fichiers de code en python, Java, C++, etc. qui sont déjà indexés par Google.
Avec une commande [filetype:csv], vous accédez ainsi aux résultats de recherche au format csv.
Par exemple, dans le cadre d’une recherche sur les matières premières, avec un mot-clé sur le café, la commande « café filetype:csv » donne accès à des exports de données en .CSV, majoritairement issues de l’OpenData.
Source : Barry Schwartz
La veille métier, une veille pas comme les autres

Faire une veille métier notamment pour les professionnels de l’information, c’est vouloir rester à la pointe, analyser les dernières tendances et dernières innovations techniques, s’approprier de nouvelles méthodologies et astuces, ou encore être en phase avec les dernières évolutions du marché, ce qui dans le contexte actuel n’est pas une mince affaire.
C’est pratiquement vital et pour autant, la veille métier reste le parent pauvre de la veille et bénéficie de beaucoup moins de visibilité que les veilles stratégique, concurrentielles, innovation, commerciales, etc. Il n’y a d’ailleurs même pas réellement de nom attitré pour ce type de veille : certains vont parler de « veille métier », de « veille personnelle », d’autres de « veille professionnelle » et parfois il n’y a aucun terme associé à la description de la démarche.
C’est bien là tout le problème de la veille métier : il s’agit d’une veille pas comme les autres, au croisement entre le personnel et le professionnel, entre l’information et la formation, et qui n'a pas vraiment de place attitrée.
Comment accéder au profil économique d'un pays et comparer ses données avec d'autres
Pour comparer des indicateurs économiques nationaux de façon simple et rapide, on est de plus en plus tenté de passer par une IA générative de contenu. Problème : le résultat n’est pas fiable et le temps de vérification peut-être très long... On recommandera plutôt le comparateur GlobalEDGE.
Créé par l'International Business Center et l'Eli Broad College of Business de la Michigan State University, GlobalEDGE est un portail Web de connaissances à l’attention des acteurs académiques et économiques et financiers permettant d’accéder au profil économique et sociétal d’un pays mais aussi de comparer les données de plusieurs pays entre elles.
En se basant sur divers indicateurs économiques, commerciaux, d'investissement, énergétiques et démographiques, il est possible de consulter et de comparer les données de 20 pays. Les données, soigneusement sourcées et vérifiées, offrent une clarté face à la complexité des informations disponibles. Par exemple, pour comparer les dépenses éducatives entre la France et l'Espagne, il suffit de choisir une année, un domaine de données, 1 à 5 indicateurs et plusieurs pays dans des menus déroulants, puis de cliquer sur Comparer pour obtenir instantanément un tableau avec les données et les sources correspondantes.
Seuls problèmes : Il lui manque une fonction d’export et également, lorsque l’on sélectionne la date, mieux vaut choisir une date précise que l’option Last available data. En effet, cette dernière n’est pas précisée et il faut donc la revérifier dans la source, ce qui peut vite devenir chronophage !
Les flux RSS, la meilleure parade à la recherche par IA ?

À l’heure où s’informer est en voie de passer par l’obtention d’une réponse unique générée par IA, comment retrouver le plaisir de découvrir et de consulter des sources fiables ?
Pour nous, journalistes, veilleurs et professionnels du Search, l’heure n’est pas vraiment à la fête. Non seulement les sources des réponses générées par IA sont englouties par ChatGPT, Bard & Co, mais aussi par les moteurs de recherche, dopés ou non à l’IA.
Voir notre nouvel article dans BASES : IA : la veille dans un monde sans sources
Et la tendance ne s’arrangera certainement pas avec Google SGE (Search Generative Experience), la nouvelle version du moteur de recherche qui utilise l’Intelligence artificielle (PALM 2) pour générer une réponse globale résumant le sujet de la recherche sous la forme d'un Google featured snippet grand format et remisant le référencement naturel en bas de page. SGE n’est pas encore disponible en France, nous disposons d’une présentation officielle ici.
Bon à savoir : créer une newsletter à partir d’un flux RSS
Avec la fermeture de l’éditeur de newsletter Revue, nombre de professionnels habitués à délivrer une newsletter par un simple export de flux RSS se sont retrouvés démunis. Une solution – ancienne, mais discrète - s’offre à eux : Goodbits.
- Pour créer sa première newsletter, connectez-vous dans Goodbits et donnez un nom à votre newsletter.
- Allez ensuite dans l’onglet « Sources » sur la gauche de l’écran et sélectionnez « RSS Feeds » pour exporter le flux RSS de votre choix.
- Collez votre lien RSS, puis cliquez sur « Add Feed ». Dans la version gratuite vous n’avez le droit qu’à un seul flux.
- A présent, vous pouvez retourner dans l’éditeur dans « Emails » et ajouter le contenu de ce flux en cliquant sur le bouton vert « Add Content ».
Sous la catégorie « Saved Links », sélectionnez la collection RSS Feed en cliquant sur le menu déroulant et vous y retrouverez l’ensemble des articles de votre flux RSS que vous pouvez à présent ‘drag and droper’ dans vote template. - Vous n’avez plus qu’à personnaliser votre Newsletter comme sur Revue.
Pour les prochaines newsletters, le flux RSS s’actualise automatiquement, nul besoin de le réimporter, il suffira de le rafraîchir (Sources > lien du RSS > bouton pour rafraîchir)
Gratuit pour 1 newsletter, envoyée à moins de 100 personnes, puis min. 24 $/mois
































